Neuron









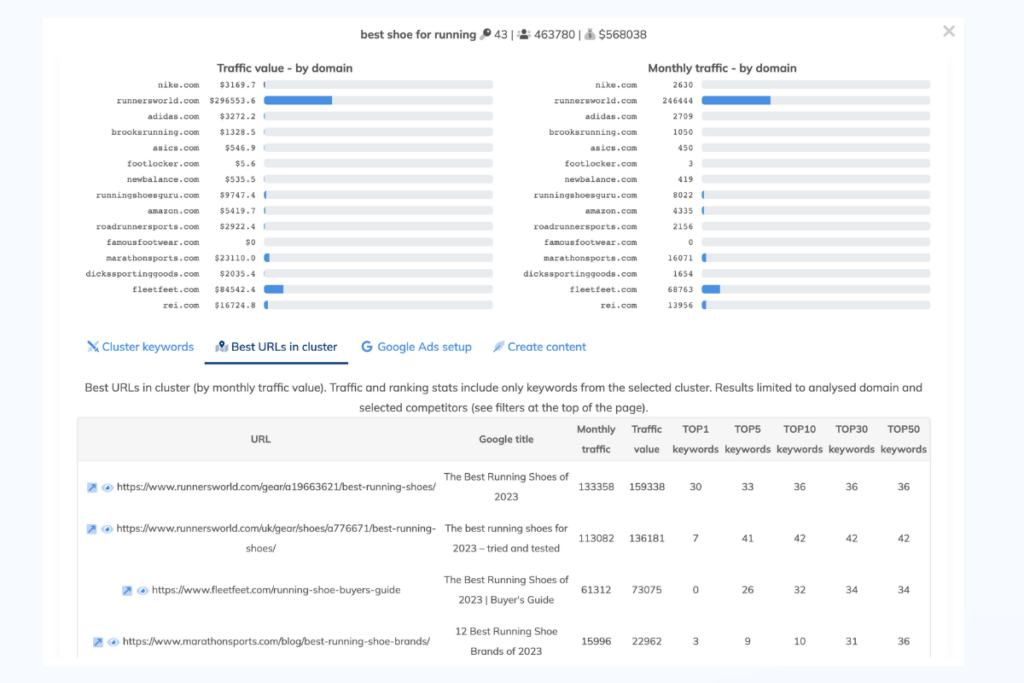
Competitive research
AI Content plan
Topical maps
Content clusters
Competitive research
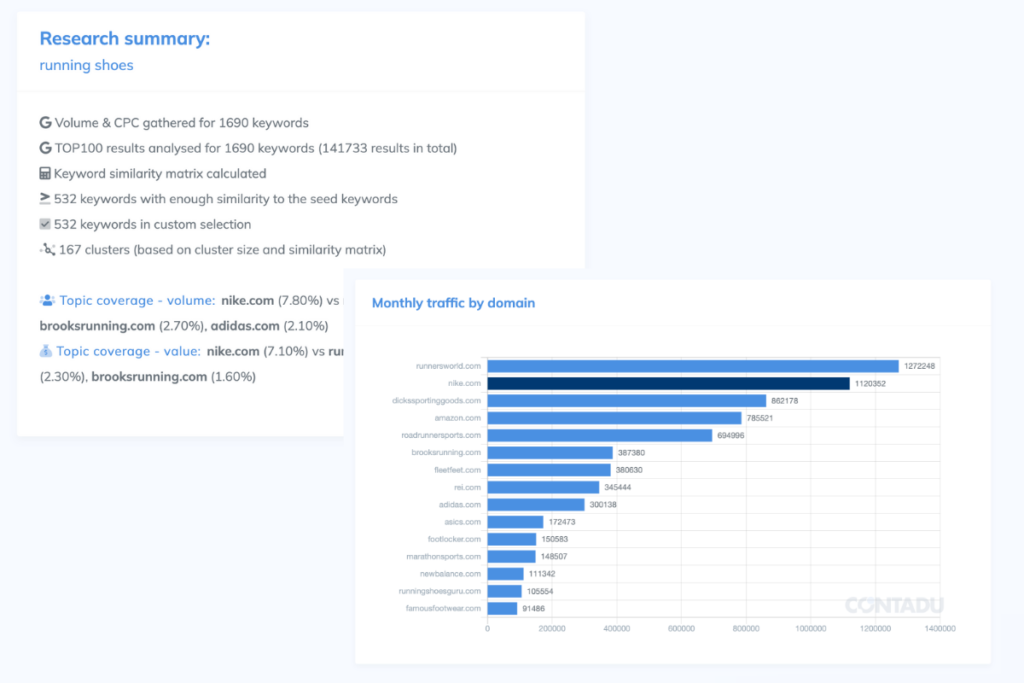
AI Content plan

Topical maps
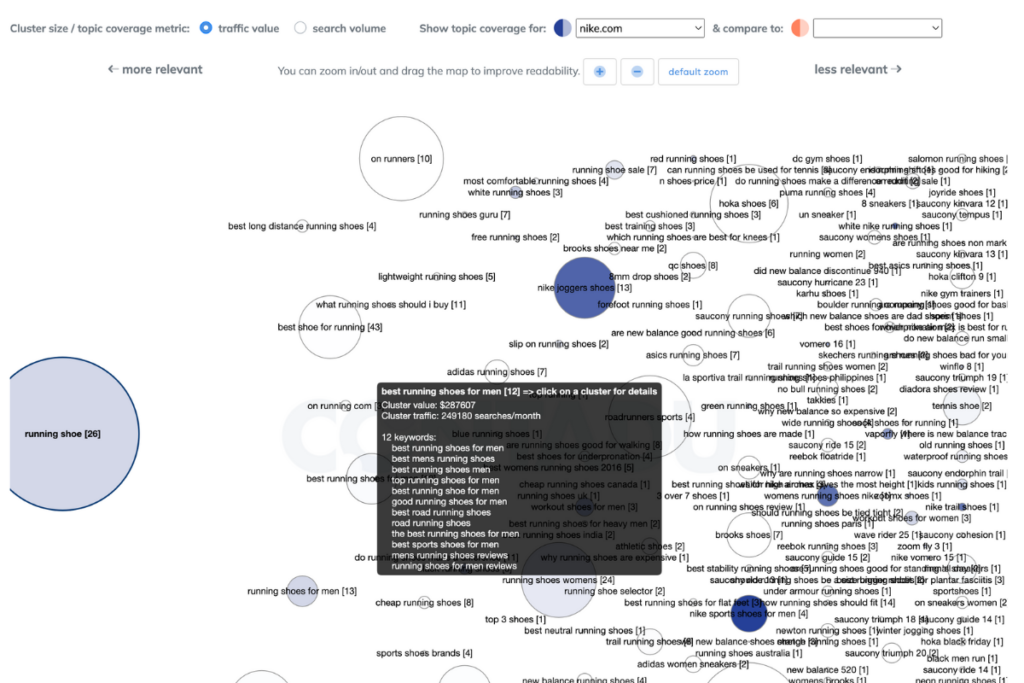
Content clusters
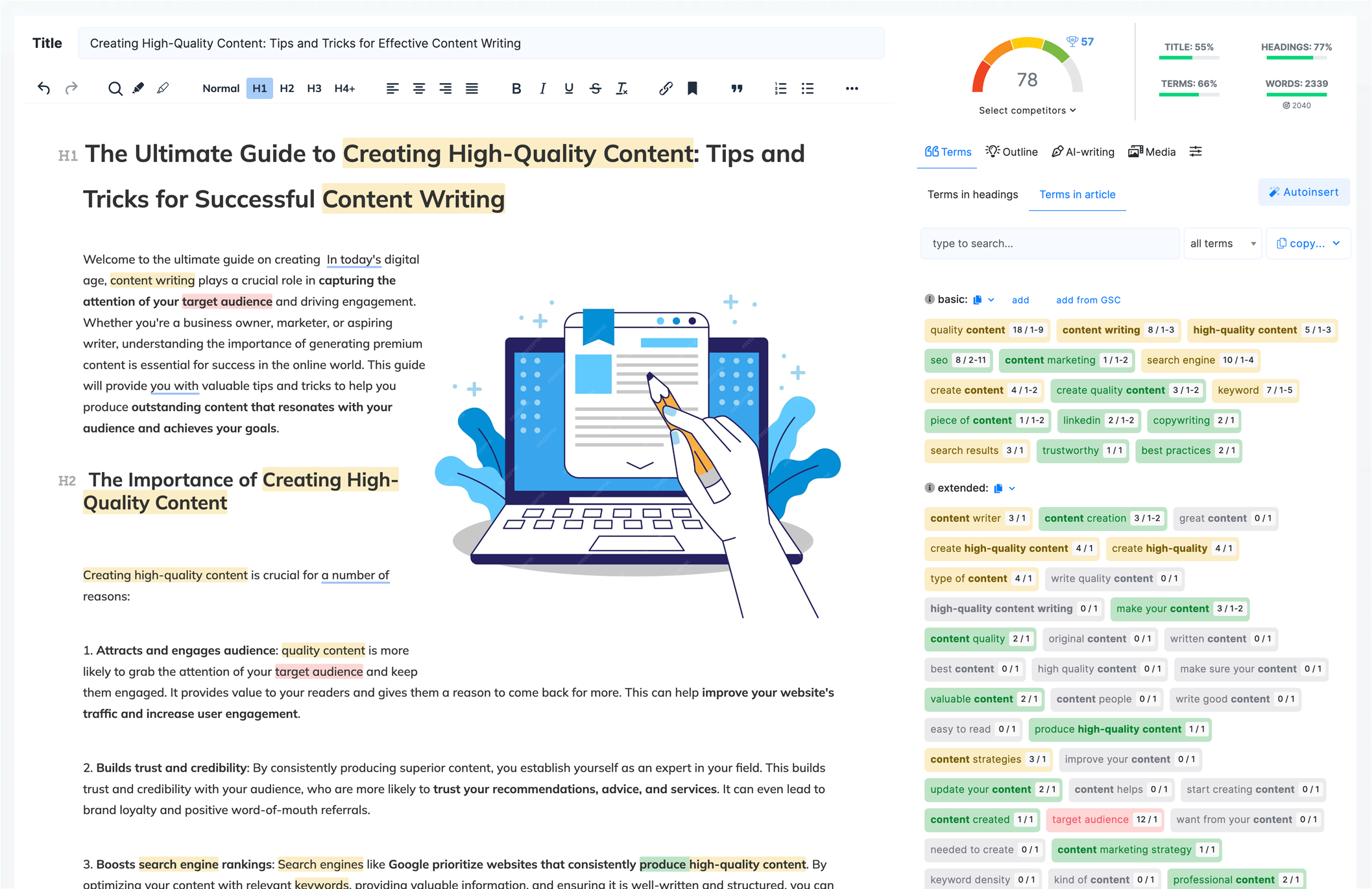
NLP Terms
Document Draft
Content Score
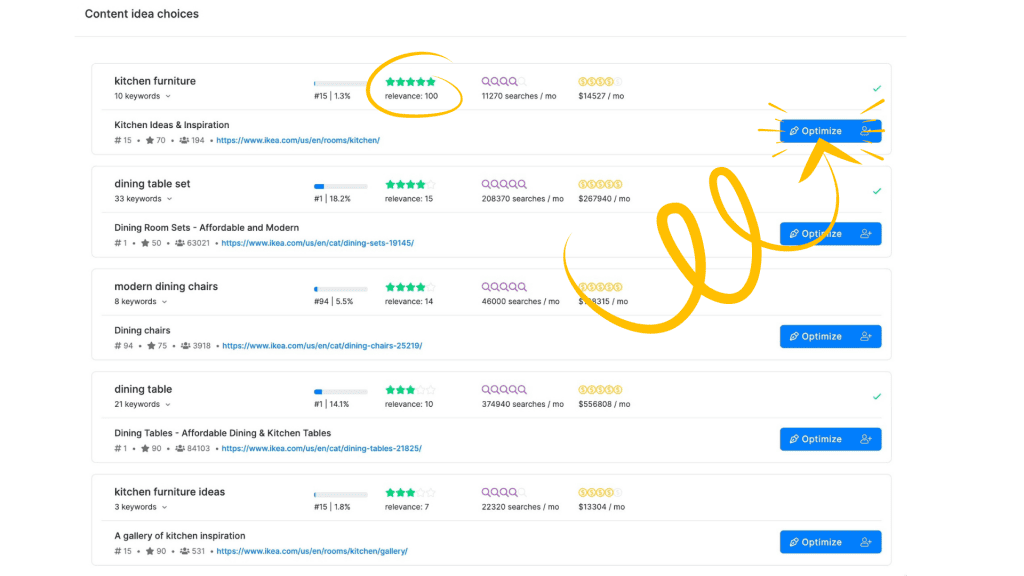
Content Ideas
AI Writing
...
NLP Terms

Document Draft

Content Score

Content Ideas

AI Writing

...

Content Ideas
Content plan
Content manager
Content publishing
Content Ideas

Content plan

Content manager

Content publishing


Start with one keyword
you want to rank for in Google
Competitors' analysis
is ready in a few seconds
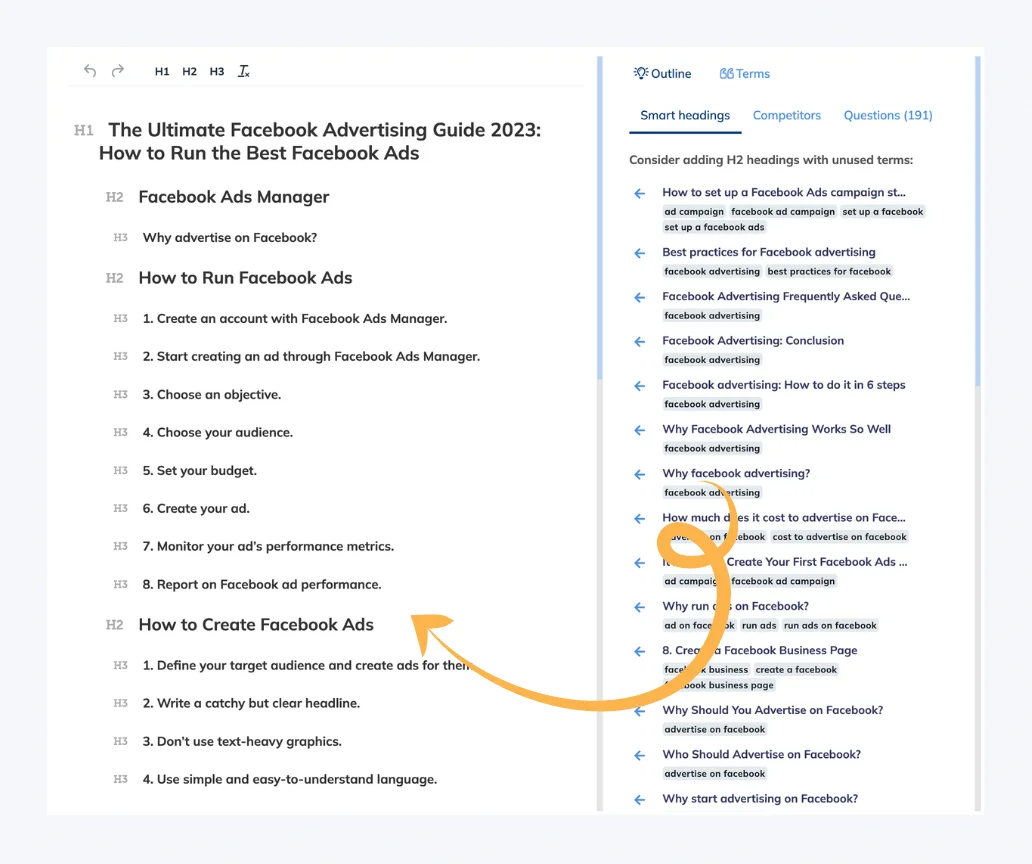
Create a document draft
including popular questions & topics
Use recommendations
& GPT AI to write the best content
Start with one keyword
you want to rank for in Google

Competitors' analysis
is ready in a few seconds

Create a document draft
including popular questions & topics

Use recommendations
& GPT AI to write the best content







